I like to hit the ground running when starting work in a repository. And I want my colleagues to get up and running quickly as well.
One thing I picked up from Anthropics Harnesses for long running agents last November was creating an init script that sets everything up in a runnable and testable state.
Run the script, get to work. It only costs one prompt, once, to make, and every time after that is deterministic and fast.
It is one of those things where I go: "Why didn't I think of that before?". And an un-metered, local, model is powerful enough to do it while I do something else. It only took two minutes, so not too bad.
Why make an init script for Firehose (this blog) now?
The best time to make an init script is when you start the project. The second best time is now.
I had Firehose running on another machine already. Running one command is usually enough to set up a Phoenix Liveview project, but I had just added another javascript dependency that was not covered by that. So instead of adding that by hand, and figuring out how to do that, I improved the process by adding the init script now.
I know now that it pays off very quickly. I had just used another project that had an init script on a new machine. No need to remember, it just works. I like software that "just works".
It is very satisfying when it runs, as you get an overview of next steps you can take. I like 'micro prompts' like these. And it paid of immediately, I will explain after the screenshot.
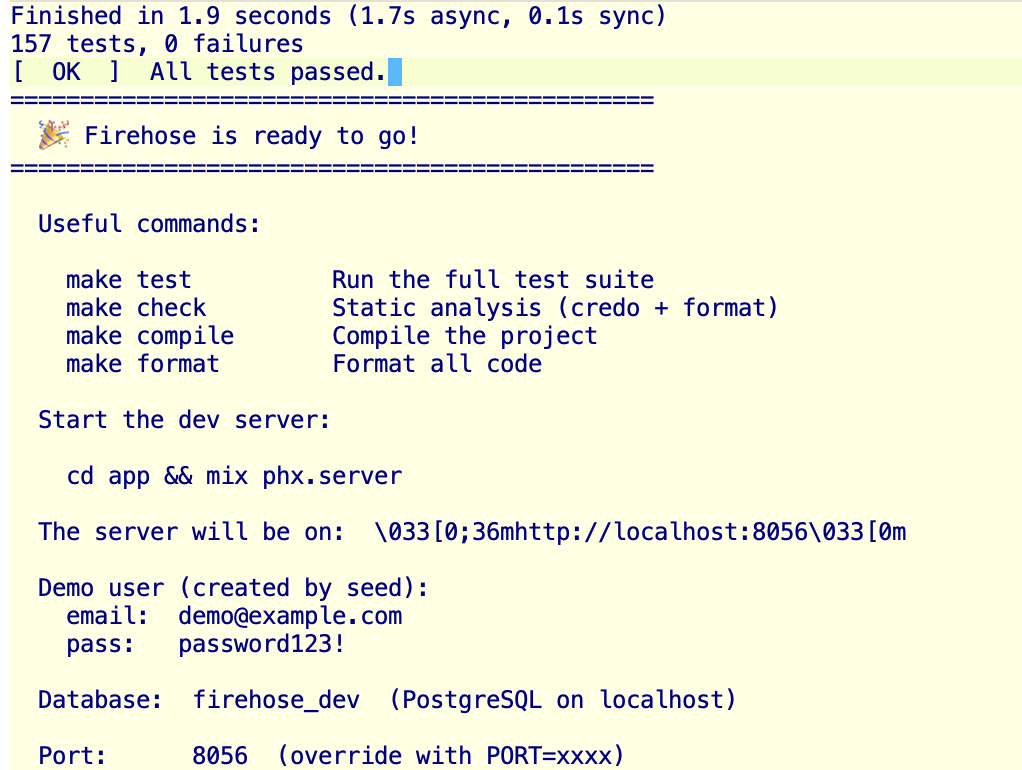
When I started the server, the port was already taken. As the script outputs the PORT variable, I knew immediately what to do, set the port and got to work.
Aside: starting the server is now muscle memory for me, and standard in Phoenix Liveview, no need to script, although the generated init script does have a --server option for those who don't know. Executable documentation for the win.
This was one fairly lazy prompt:
I think it would be handy to have an init script for this repository that also downloads the js dependencies. the init.sh script should get the dependencies, run the mix setup so there is a working db, run the tests and download the js assets. the goal
is for an agent or a person to be able to start working. At the end of the script, print handy instructions e.g. to run make, and what PORT the server will run on
It only took this prompt. It did take quite a few turns. My Pi turn-limit extension alerted me that it had gone over 25 turns. I chose not to let Pi run further. What happened was that the agent was done, but it did not have permissions to actually run the init script because the sandbox did not allow everything in it. So I ran that by hand outside the sandbox.
Do you have init scripts or something like it? Would it be useful to you? What do you think?
Further reading
A Full ;-), very brief transcript of the session, so you can see all the turns taken in detail.
I wrote earlier on the QWAN blog about working deterministically where possible, and the pay-offs in Stochastic to Deterministic. Even though my local model is un-metered, running a script is still a lot faster and much more predictable.
I used the 35B model from my local agentic dev setup It was more than up to the job. Sandboxing is a bit of work though.
Bonus item - what the init script does, and local agent performance
According to the agent:
- Pre-flight checks — verifies elixir, mix, node, npm, and PostgreSQL are available
- make deps — fetches all Elixir dependencies
- mix ecto.setup — creates the DB, runs migrations, seeds demo user
- npm install — installs JS dependencies (highlight.js, etc.) in assets/
- mix assets.setup && mix assets.build — installs esbuild/tailwind and bundles the JS/CSS
- make test — runs the full test suite
It ends with a summary showing how to start the server (port 8056), demo credentials, and handy make commands.
The snippet below is from my performance widget. Token generation is not super fast, but all 32 turns ran while attending Chris Parsons' webinar. 2.5 minutes for a script that just works; is good enough for me.
📊 Performance: llama.cpp/Qwen3.6-35B-A3B-MXFP4-MOE.gguf
Prefill: 28,376 tokens @ 5253.8 tok/s
Generation: 5,699 tokens @ 38.8 tok/s
Combined: 34,075 tokens @ 223.5 tok/s (2.5m total)
TTFT: 5401ms
Turns: 32
Things don't always go to plan
I am integrating the Microprints library that I open sourced earlier - to keep an eye on changes. My local model seems to have trouble getting the correct files to render. I fixed most of the CSS issues (Claude Opus 4.6 struggled with that as well). I am still learning about how to make Phoenix Liveview applications modular, some of that can be done by reading, other learning happens the hard way.
Further Reading
Graham Lee wrote a pattern Replace Vibes with Tools that gives some more context to this way of working.
Back in December I wrote Stochastic to Deterministic in which I attempt to explain my line of thinking more generally.