Prototyping fairly deep and fast
This text from "The problem" section onwards was lightly edited by me, the first pass was generated by a coding agent, based on the session the prototype was developed in. It is not the tone I would write in, but there is something to it. I've written more commentary on the writing and development process in the Afterword.
Prototyping is like a mirror - what is wanted (and what not) is clearer after it has been built. Building quality in, even for a prototype, can let the exploration go deeper, in more detail without spiraling out of control.
A collaboratory is a metaphor for a federated intranet-like setup, where various parties can share information. Each party can have a requisite variety of detail for their own operations, and share what is beneficial and legal to share through a central system. I spent a day building a prototype to get clarity on the solution space for a problem in a corporate client, based on three design principles outlined below. ACME corporation and its clients are, of course, fictional. I have seen and solved similar problems in other companies - also in government.
I left the 'several weeks' remarks in the text - it would easily have cost this building completely by hand with a small team.
A full collaboratory would consist of many slices. I focused on one slice, a fictional sharing of cases, to illustrate the idea, answer some of our hypotheses and drive out more questions. Working, full stack, software is a great conversation starter.
The problem
Acme Corporation is a sprawling professional-services group. Dozens of business units (BUs), tens of thousands of people, and every year a pile of bids going out to clients that — more often than not — other parts of Acme have already worked with.
The BUs bid in silos. Cross-sell signals are invisible. Referrals happen by accident, over coffee, between people who happen to know each other. Every BU has its own spreadsheet, its own "case list", its own definition of what a "won bid" means. And every attempt to build a single central system has failed — either because a BU refuses to hand over sensitive financial data, or because the thing that gets built is so generic no team actually uses it.
The challenge here is editorial, not technical. Getting BUs to contribute useful information in a form that other BUs can act on — without leaking margin, PII, or export-controlled content — is the hard part.
I built a proof of concept to test whether there's a shape of system that actually threads this needle. Here's what came out of it, and the three principles I'd stand behind if I had to pitch this to a CFO.
What I built
A Phoenix LiveView app called Case Insights. Each BU runs its own instance — a spoke. A thin central service — the Hub — receives redacted projections of closed cases from every spoke and exposes cross-BU intelligence back to anyone who needs it.
Feature-complete-enough-to-demo in a handful of weeks:
- Case Explorer — browse, filter, and drill into cases owned by your BU, with full parent/child case trees.
- Bid Preparation — type in a prospective client and get a three-tier answer: "your BU has worked with them before" / "another Acme BU has worked with them" / "here's what peers in your sector have done with similar clients".
- Nomination flow — a lightweight "ask a colleague" loop for pulling in knowledge that lives in someone's head rather than a system.
- Analytics — portfolio summaries, lifetime-value-by-client, win-reason breakdowns.
- CSV import — three-step wizard for bulk-seeding a BU from whatever spreadsheet they already have.
- Hub export pipeline — the piece that makes federation actually work.
313 tests passing. Real redaction. Real versioned exports. Not a mock.
Principle 1 — Federation, not centralisation
Every attempt I've seen at "one central system for the whole group" has either failed politically or decayed into a lowest-common-denominator tool that nobody trusts. So I didn't build one.
Instead: each BU owns their own spoke. Their data lives in their instance. Their financial detail never leaves unless they choose to expose it, and even then, never raw. The Hub is thin on purpose — it holds a redacted projection and nothing else.
And crucially, BUs can opt in at three different levels, depending on how much appetite they have:
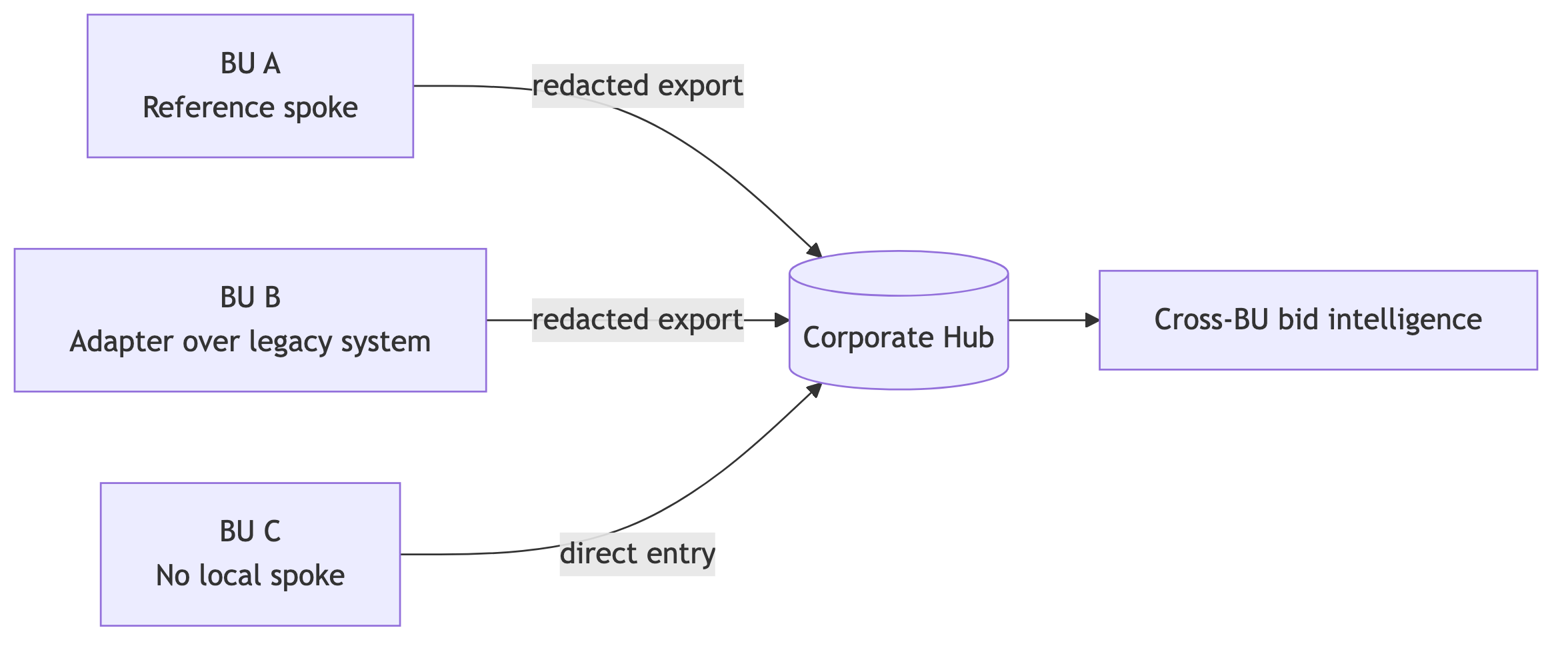
- Tier 1 — Reference implementation. Run the open-source spoke as-is. Fastest path. Best for BUs without a CRM or with a weak one.
- Tier 2 — Adapter. Keep your existing case/CRM system. Write a small adapter that maps your records onto the Hub's export contract. Gives you federation without a migration.
- Tier 3 — Plug in to central. No local infrastructure at all. Users log into a shared central instance and contribute directly. Useful for small BUs where running a spoke isn't worth it.
A CFO can roll this out without a big-bang. Pick the BUs with the hungriest bid managers, run them at Tier 1. Let reluctant BUs sit at Tier 3. Let the BUs with entrenched systems do Tier 2 on their own timeline. Each tier delivers value independently. Nothing blocks on everyone agreeing.
Principle 2 — Loosely coupled, cohesive
The whole point is to preserve BU autonomy while enabling cross-BU intelligence. These two things sound contradictory but they're not — they just need the contract between Hub and spoke to be very narrow.
The Hub sees:
- Who (client name, sector)
- Which BU worked with them
- When (year)
- Outcome (won / lost, a summary, a narrative)
- Rough scale (a value band, not a number)
- Structural hints (does this case have follow-on work? Is it linked to a parent case?)
The Hub does not see:
- Margin, staff retention, employee satisfaction
- PII — contact names, emails, phone numbers
- The raw financials
- Who submitted the case
- Internal notes that didn't make it into the narrative field
Every BU keeps full control of everything inside their own instance. What they choose to publish is bounded by the contract, not by trust in the central team.
Principle 3 — Data Loss Prevention at the source
This is the bit I'm proudest of, and the bit that makes this architecture different from the usual "dump it in a data lake and scrub it later" pattern.
DLP happens at the application layer, before the data leaves the spoke. Not in a gateway. Not in a post-hoc scan. In the code that writes the export record.
Four mechanisms, composed:
- Field filtering. Sensitive fields are physically absent from the exported payload. Margin, staff retention, PII — not redacted, not masked, not in the structure. The Hub can't leak what it never receives.
- Content filtering. Raw financial values are translated into bands (
<500K,500K–2M,2M+) at export time. A reader on the Hub can see that a deal was "meaningful" without knowing the number. - Per-field visibility tiers. Inside a BU, the same case is rendered differently depending on who's looking at it — owner, BU admin, BU member, cross-BU viewer, or hidden entirely. One policy, applied consistently everywhere the case is read.
- Export restrictions. Cases can be withheld entirely based on policy — draft, incomplete, or (in the next iteration) country-specific export controls like ITAR or EU dual-use. The spec has a slot for a content scanner that inspects narrative text for export-controlled material. The Hub only ever receives what's cleared.
Versioning is built in. Every export is numbered. If a BU enriches a case after the fact, the Hub gets a new version and can reconcile. Nothing is ever silently overwritten.
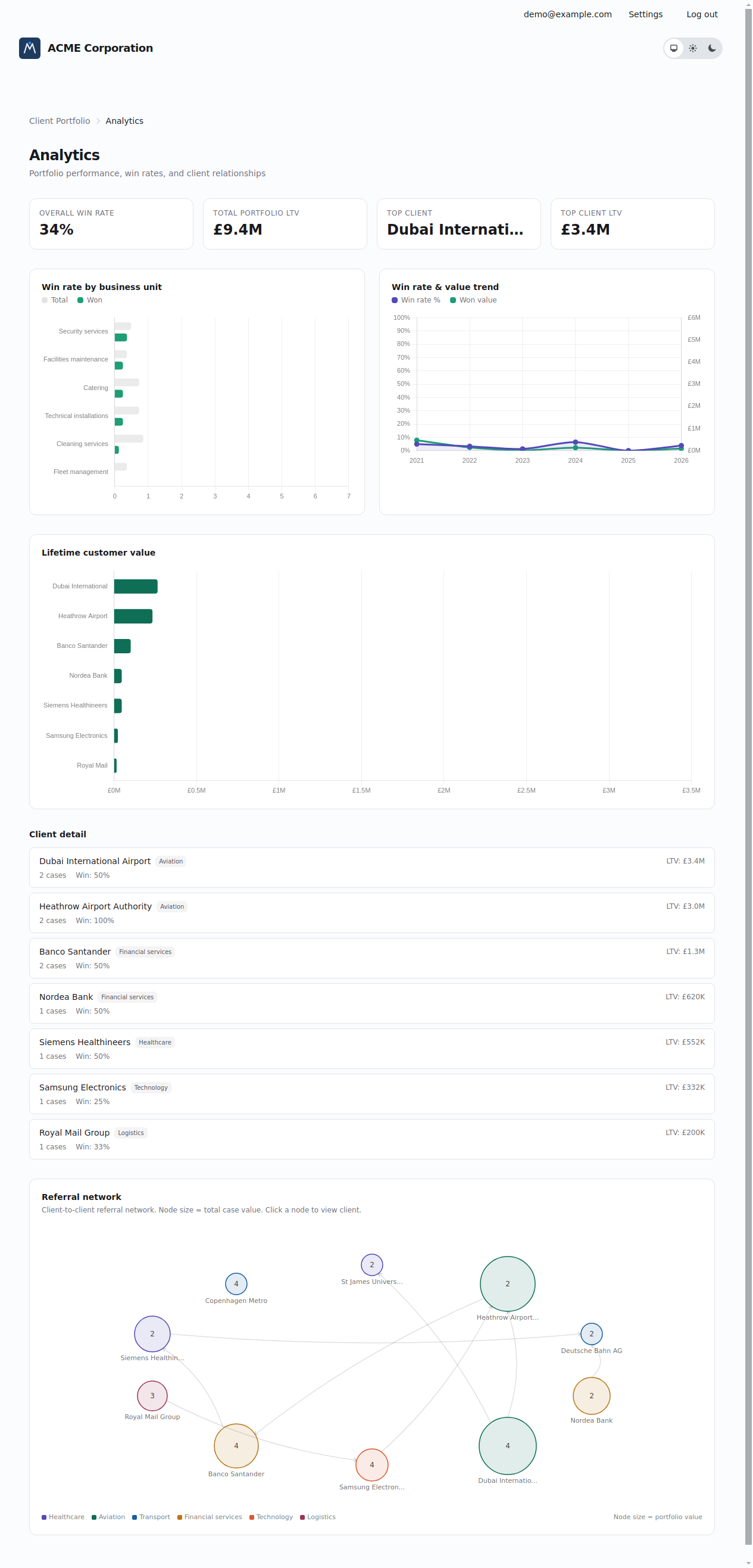
Why a POC got this far, this fast
Three things made the build feel unreasonably quick:
-
Spec-first design. I wrote the domain rules in a spec language (Allium) before writing any code. Entities, enums, state machines, redaction rules, access-control tiers — all of it agreed on paper first. When it came time to code, the shape was already locked. Almost no rework.
-
AI-assisted build loop. The specs are machine-readable, so I could hand them to an LLM alongside the existing code and get implementation that actually matched the intent. The rare drift got caught fast because the spec was the source of truth.
-
Phoenix LiveView. Server-rendered reactivity. I built the whole UI — case explorer, bid prep wizard, nomination flow, CSV import, analytics — without a JavaScript framework. Forms, tables, charts, modals, all in one codebase.
The hard problem was never the code. It was agreeing what to build. Once the spec was right, the build was a formality.
What a CFO should take away
- Federation is achievable. You don't need to centralise to get cross-BU intelligence. A thin Hub plus narrow contracts plus per-BU spokes beats a mega-system.
- DLP at source is cheaper than DLP at the perimeter. Filtering in the application layer, with the domain model in front of you, is vastly easier than trying to scrub a lake after the fact. It's also legally cleaner — the sensitive data never left the BU.
- Opt-in tiers avoid the big-bang trap. The reason central systems fail isn't usually technical — it's that rollout requires unanimous agreement. Three tiers let each BU join on their own terms. Value compounds as more BUs join, but no single BU is blocking the others.
- Spec-first design pays back quickly. A week of elicitation saved weeks of rework. In a world where the LLMs can write most of the code, the bottleneck moves to understanding what you want.
If you're at a large organisation and you're still trying to solve a cross-BU knowledge problem by building a single centralised CRM, this is the shape I'd argue you should be looking at instead. It's not a data lake. It's not a warehouse. It's a federation of small, opinionated tools that share one narrow contract, with DLP baked into the contract itself.
The POC exists. The redaction works. The tests pass. It would ship.
Afterword
(written by hand)
I created this and the follow on blog post with a single prompt (for a plan) and some iteration on what the audience should be etc.
I told the agent to write for a more general audience. The "What a CFO should take away" section is a good example of that. "Why a PO got this far, this fast" does get a bit more technical than I expected. See it as an FYI, but I am confident some of my more technical readers will appreciate it.
I did find some defects in the software preparing the blog posts. One of the screenshots in the auto-generated demo contained a clear error. Working in somewhat smaller steps could have prevented this. I wanted to see where the solution went, quickly. For production work I check the tests and code against the spec, update any of them as needed, and look more closely at what was produced, including e.g. exploratory testing and user feedback.
The agent mentions "Spec-first development". There was a formal specification involved, not just text. The process was more an iterative conversation than writing the spec out in full before starting. But this was hours, not weeks as it was just me and the animatronic rubber duck in the chat. Making tacit knowledge explicit takes people and time. Working software can help to flush that out, combined with workshops. More about the formal specification in the next post.
Acknowledgements
Thanks to Antony Marcano for feedback on the first version. I moved my commentary in to the afterword to improve reading flow. Mixing my comments with the agents narrative was indeed confusing.